
aNewDomain  — If you think fake news and conspiracy theories on the Internet are bad now, look out.
— If you think fake news and conspiracy theories on the Internet are bad now, look out.
University of Washington researchers this week demonstrated a new technique for creating realistic-looking ‘synthesized videos’ of people saying things they never did..
As part of their new study [PDF], the researchers came up with a neural network-powered technique of grabbing existing audio, video and photos of Obama to create an entirely new video of him.
The creation of such video was possible before, but it required enormous time and effort to analyze all the rich data around the complexities of a given individual’s facial movements as they correspond to the sound of his or her voice.
The new synthesized video technique demonstrated here, said researchers, uses neural network algorithms and digital video available on the Internet to dramatically reduce the effort required to create such videos. The technology isn’t designed to improve the prospects of conspiracy theorists and fake video wannabes, of course.
Funded by the university along with Google, Facebook, Samsung and Intel, the work’s intent was to dramatically improve video conferencing by filling in missing or dropped frames. It’s also a natural for VR, AR and entertainment production, researchers said.
Fake news makers, conspiracy theorists and others out to dupe the public are, unfortunately, going to love this stuff.
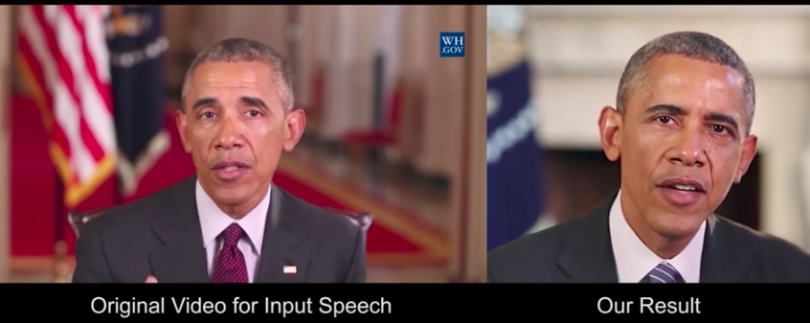
To see what I mean, take a look at the following synthesized video, which the researchers released along with their research paper this week. It features the real Barack Obama and the synthesized Obama speaking side by side.
Earlier this year, the same researchers showed how just analyzing photos and videos on the Internet is the first step toward creating talking, real-looking models of just about anyone — because just about everyone has photos and videos of themselves online.
To create the Obama video, the researchers first used a recurring neural network tech to scrutinize millions of frames of the former president from ours of his weekly weekly presidential addresses over his eight years in office. It then created a detailed map of how all the changes in shape of his mouth as he spoke.
“Using the mouth shape mapped at each time instant, we synthesize high quality mouth texture, and composite it with proper 3D pose matching to change what he appears to be saying in a target video to match the input audio track,” the scientists write. “Our approach produces photorealistic results.”
Agreed. It’s so photorealistic that it’s actually, well, a bit scary.
Synthesized Obama: Coming soon to a Twitter or Facebook feed near you?
The researchers are careful to say up front that they didn’t make their synthesized Obama dopelganger say anything he hadn’t said before. That is, they didn’t put words in his mouth.
But that doesn’t mean someone else won’t, said Supasorn Suwajanakorn, the study’s lead researcher. Fake video creation are “likely (to be) possible soon,” he said.
If there’s a silver lining to that thinking, it’s this. The new synthesized video techniques also will inform the creation of tools that can spot fake video, Suwajanakorn said.
University of Washington researchers will deliver the results of their study, which was co-funded by Samsung, Google, Facebook and Intel, at SIGGRAPH on Aug. 2.
Stay tuned.
For aNewDomain and the new RobotRepublic, I’m Gina Smith.
Read the study in full and in place, below.
Research- Faking Video With AI by Gina Smith on Scribd











